Druid v0.20.0 Release Notes
Release Date: 2020-10-17 // over 3 years ago-
📚 Apache Druid 0.20.0 contains around 160 new features, bug fixes, performance enhancements, documentation improvements, and additional test coverage from 36 contributors. Refer to the complete list of changes and everything tagged to the milestone for further details.
# New Features
# Ingestion
# Combining InputSource
👀 A new combining InputSource has been added, allowing the user to combine multiple input sources during ingestion. Please see https://druid.apache.org/docs/0.20.0/ingestion/native-batch.html#combining-input-source for more details.
# Automatically determine numShards for parallel ingestion hash partitioning
When hash partitioning is used in parallel batch ingestion, it is no longer necessary to specify
numShardsin the partition spec. Druid can now automatically determine a number of shards by scanning the data in a new ingestion phase that determines the cardinalities of the partitioning key.# Subtask file count limits for parallel batch ingestion
👍 The size-based
splitHintSpecnow supports a newmaxNumFilesparameter, which limits how many files can be assigned to individual subtasks in parallel batch ingestion.The segment-based
splitHintSpecused for reingesting data from existing Druid segments also has a newmaxNumSegmentsparameter which functions similarly.👀 Please see https://druid.apache.org/docs/0.20.0/ingestion/native-batch.html#split-hint-spec for more details.
# Task slot usage metrics
🆕 New task slot usage metrics have been added. Please see the entries for the
taskSlotmetrics at https://druid.apache.org/docs/0.20.0/operations/metrics.html#indexing-service for more details.# Compaction
👍 # Support for all partitioning schemes for auto-compaction
📚 A partitioning spec can now be defined for auto-compaction, allowing users to repartition their data at compaction time. Please see the documentation for the new
partitionsSpecproperty in the compactiontuningConfigfor more details:🔧 https://druid.apache.org/docs/0.20.0/configuration/index.html#compaction-tuningconfig
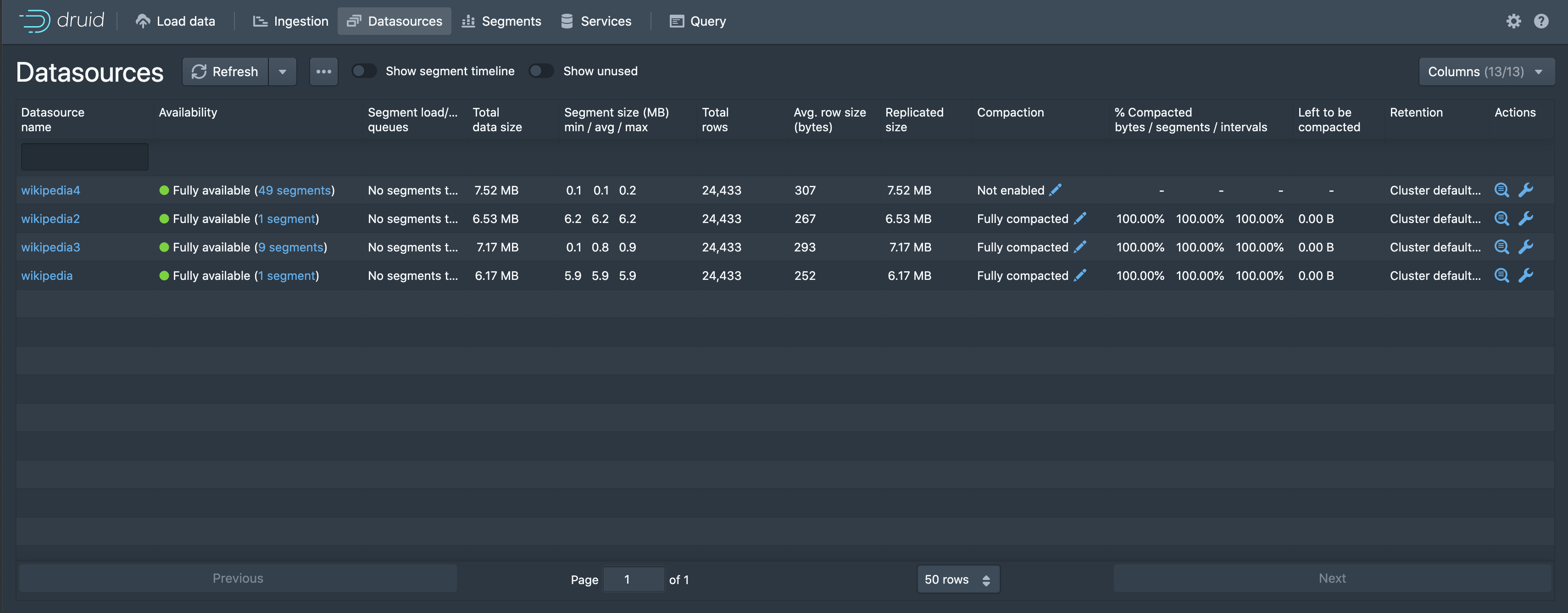
# Auto-compaction status API
A new coordinator API which shows the status of auto-compaction for a datasource has been added. The new API shows whether auto-compaction is enabled for a datasource, and a summary of how far compaction has progressed.
⚡️ The web console has also been updated to show this information:
https://user-images.githubusercontent.com/177816/94326243-9d07e780-ff57-11ea-9f80-256fa08580f0.png
👀 Please see https://druid.apache.org/docs/latest/operations/api-reference.html#compaction-status for details on the new API, and https://druid.apache.org/docs/latest/operations/metrics.html#coordination for information on new related compaction metrics.
# Querying
# Query segment pruning with hash partitioning
👍 Druid now supports query-time segment pruning (excluding certain segments as read candidates for a query) for hash partitioned segments. This optimization applies when all of the
partitionDimensionsspecified in the hash partition spec during ingestion time are present in the filter set of a query, and the filters in the query filter on discrete values of thepartitionDimensions(e.g., selector filters). Segment pruning with hash partitioning is not supported with non-discrete filters such as bound filters.0️⃣ For existing users with existing segments, you will need to reingest those segments to take advantage of this new feature, as the segment pruning requires a
partitionFunctionto be stored together with the segments, which does not exist in segments created by older versions of Druid. It is not necessary to specify thepartitionFunctionexplicitly, as the default is the same partition function that was used in prior versions of Druid.0️⃣ Note that segments created with a default
partitionDimensionsvalue (partition by all dimensions + the time column) cannot be pruned in this manner, the segments need to be created with an explicitpartitionDimensions.# Vectorization
👀 To enable vectorization features, please set the
druid.query.default.context.vectorizeVirtualColumnsproperty totrueor set thevectorizeproperty in the query context. Please see https://druid.apache.org/docs/0.20.0/querying/query-context.html#vectorization-parameters for more information.👍 # Vectorization support for expression virtual columns
🐎 Expression virtual columns now have vectorization support (depending on the expressions being used), which an results in a 3-5x performance improvement in some cases.
👀 Please see https://druid.apache.org/docs/0.20.0/misc/math-expr.html#vectorization-support for details on the specific expressions that support vectorization.
👍 # More vectorization support for aggregators
👍 Vectorization support has been added for several aggregation types: numeric min/max aggregators, variance aggregators, ANY aggregators, and aggregators from the
druid-histogramextension.#10260 - numeric min/max
#10304 - histogram
#10338 - ANY
#10390 - variance🐎 We've observed about a 1.3x to 1.8x performance improvement in some cases with vectorization enabled for the min, max, and ANY aggregator, and about 1.04x to 1.07x wuth the histogram aggregator.
#
offsetparameter for GroupBy and Scan queries👀 It is now possible set an
offsetparameter for GroupBy and Scan queries, which tells Druid to skip a number of rows when returning results. Please see https://druid.apache.org/docs/0.20.0/querying/limitspec.html and https://druid.apache.org/docs/0.20.0/querying/scan-query.html for details.#
OFFSETclause for SQL queries👀 Druid SQL queries now support an
OFFSETclause. Please see https://druid.apache.org/docs/0.20.0/querying/sql.html#offset for details.# Substring search operators
Druid has added new substring search operators in its expression language and for SQL queries.
Please see documentation for
CONTAINS_STRINGandICONTAINS_STRINGstring functions for Druid SQL (https://druid.apache.org/docs/0.20.0/querying/sql.html#string-functions) and documentation forcontains_stringandicontains_stringfor the Druid expression language (https://druid.apache.org/docs/0.20.0/misc/math-expr.html#string-functions).🐎 We've observed about a 2.5x performance improvement in some cases by using these functions instead of
STRPOS.# UNION ALL operator for SQL queries
👀 Druid SQL queries now support the
UNION ALLoperator, which fuses the results of multiple queries together. Please see https://druid.apache.org/docs/0.20.0/querying/sql.html#union-all for details on what query shapes are supported by this operator.0️⃣ # Cluster-wide default query context settings
It is now possible to set cluster-wide default query context properties by adding a configuration of the form
druid.query.override.default.context.*, with*replaced by the property name.# Other features
💻 # Improved retention rules UI
0️⃣ The retention rules UI in the web console has been improved. It now provides suggestions and basic validation in the period dropdown, shows the cluster default rules, and makes editing the default rules more accessible.
# Redis cache extension enhancements
💅 The Redis cache extension now supports Redis Cluster, selecting which database is used, connecting to password-protected servers, and period-style configurations for the
expirationandtimeoutproperties.# Disable sending server version in response headers
It is now possible to disable sending of server version information in Druid's response headers.
0️⃣ This is controlled by a new property
druid.server.http.sendServerVersion, which defaults totrue.🔧 # Specify byte-based configuration properties with units
🔧 Druid now supports units for specifying byte-based configuration properties, e.g.:
druid.server.maxSize=300gequivalent to
druid.server.maxSize=300000000000👀 Please see https://druid.apache.org/docs/0.20.0/configuration/human-readable-byte.html for more details.
🛠 # Bug fixes
# Fix query correctness issue when historical has no segment timeline
🛠 Druid 0.20.0 fixes a query correctness issue when a broker issues a query expecting a historical to have certain segments for a datasource, but the historical when queried does not actually have any segments for that datasource (e.g., they were all unloaded before the historical processed the query). Prior to 0.20.0, the query would return successfully but without the results from the segments that were missing in the manner described previously. In 0.20.0, queries will now fail in such situations.
# Fix issue preventing result-level cache from being populated
🛠 Druid 0.20.0 fixes an issue introduced in 0.19.0 (#10337) which can prevent query caches from being populated when result-level caching is enabled.
# Fix for variance aggregator ordering
The variance aggregator previously used an incorrect comparator that compared using an aggregator's internal
countvariable instead of the variance.# Fix incorrect caching for groupBy queries with limit specs
🛠 Druid 0.20.0 fixes an issues with groupBy queries and caching, where the limitSpec of the query was not considered in the cache key, leading to potentially incorrect results if queries that are identical except for the limitSpec are issued.
# Fix for
stringFirstandstringLastwith rollup enabled👻 #7243 has been resolved, the
stringFirstandstringLastaggregators no longer cause an exception when used during ingestion with rollup enabled.⬆️ # Upgrading to Druid 0.20.0
🚀 Please be aware of the following considerations when upgrading from 0.19.0 to 0.20.0. If you're updating from an earlier version than 0.19.0, please see the release notes of the relevant intermediate versions.
0️⃣ # Default
maxSize0️⃣
druid.server.maxSizewill now default to the sum ofmaxSizevalues defined within thedruid.segmentCache.locations. The user can still provide a custom value fordruid.server.maxSizewhich will take precedence over the default value.# Compaction and kill task ID changes
🛠 Compaction and kill tasks issued by the coordinator will now have their task IDs prefixed by
coordinator-issued, while user-issued kill tasks will be prefixed byapi-issued.# New size limits for parallel ingestion split hint specs
0️⃣ The size-based and segment-based
splitHintSpecfor parallel batch ingestion now apply a default file/segment limit of 1000 per subtask, controlled by themaxNumFilesandmaxNumSegmentsrespectively.# New
PostAggregatorandAggregatorFactorymethods⚡️ Users who have developed an extension with custom
PostAggregatororAggregatorFactoryimplementions will need to update their extensions, as these two interfaces have new methods defined in 0.20.0.PostAggregatornow has a new method:ValueType getType();👍 To support type information on
PostAggregator,AggregatorFactoryalso has 2 new methods:public abstract ValueType getType(); public abstract ValueType getFinalizedType();👀 Please see #9638 for more details on the interface changes.
# New
Expr-related methods⚡️ Users who have developed an extension with custom
Exprimplementions will need to update their extensions, asExprand related interfaces hae changed in 0.20.0. Please see the PR below for details:# More accurate
query/cpu/timemetricIn 0.20.0, the accuracy of the
query/cpu/timemetric has been improved. Previously, it did not account for certain portions of work during query processing, described in more detail in the following PR:🌲 # New audit log service metric columns
➕ If you are using audit logging, please be aware that new columns have been added to the audit log service metric (
comment,remote_address, andcreated_date). An optionalpayloadcolumn has also been added, which can be enabled by settingdruid.audit.manager.includePayloadAsDimensionInMetrictotrue.🔊 #
sqlQueryContextin request logs🌲 If you are using query request logging, the request log events will now include the
sqlQueryContextfor SQL queries.📇 # Additional per-segment state in metadata store
📇 Hash-partitioned segments created by Druid 0.20.0 will now have additional
partitionFunctiondata in the metadata store.➕ Additionally, compaction tasks will now store additional per-segment information in the metadata store, used for tracking compaction history.
# Known issues
#
druid.segmentCache.locationSelectorStrategyinjection failure👀 Specifying a value for
druid.segmentCache.locationSelectorStrategyprevents services from starting due to an injection error. Please see #10348 for more details.🌐 # Resource leak in web console data sampler
👀 When a timeout occurs while sampling data in the web console, internal resources created to read from the input source are not properly closed. Please see #10467 for more information.
# Credits
🚀 Thanks to everyone who contributed to this release!
@a2l007
@abhishekagarwal87
@abhishekrb19
@ArvinZheng
@belugabehr
@capistrant
@ccaominh
👕 @clintropolis
@code-crusher
@dylwylie
@fermelone
@FrankChen021
@gianm
@himanshug
@jihoonson
@jon-wei
@josephglanville
@joykent99
@kroeders
@lightghli
@lkm
@mans2singh
@maytasm
@medb
@mghosh4
@nishantmonu51
@pan3793
@richardstartin
@sthetland
@suneet-s
@tarunparackal
@tdt17
@tourvi
@vogievetsky
@wjhypo
@xiangqiao123
@xvrl
{kind=link}
Previous changes from v0.19.0
-
📚 Apache Druid 0.19.0 contains around 200 new features, bug fixes, performance enhancements, documentation improvements, and additional test coverage from 51 contributors. Refer to the complete list of changes and everything tagged to the milestone for further details.
# New Features
0️⃣ # GroupBy and Timeseries vectorized query engines enabled by default
✅ Vectorized query engines for GroupBy and Timeseries queries were introduced in Druid 0.16, as an opt in feature. Since then we have extensively tested these engines and feel that the time has come for these improvements to find a wider audience. Note that not all of the query engine is vectorized at this time, but this change makes it so that any query which is eligible to be vectorized will do so. This feature may still be disabled if you encounter any problems by setting
druid.query.vectorizetofalse.👍 # Druid native batch support for Apache Avro Object Container Files
🆕 New in Druid 0.19.0, native batch indexing now supports Apache Avro Object Container Format encoded files, allowing batch ingestion of Avro data without needing an external Hadoop cluster. Check out the docs for more details
⚡️ # Updated Druid native batch support for SQL databases
👀 An 'SqlInputSource' has been added in Druid 0.19.0 to work with the new native batch ingestion specifications first introduced in Druid 0.17, deprecating the SqlFirehose. Like the 'SqlFirehose' it currently supports MySQL and PostgreSQL, using the driver from those extensions. This is a relatively low level ingestion task, and the operator must take care to manually ensure that the correct data is ingested, either by specially crafting queries to ensure no duplicate data is ingested for appends, or ensuring that the entire set of data is queried to be replaced when overwriting. See the docs for more operational details.
# Apache Ranger based authorization
📚 A new extension in Druid 0.19.0 adds an Authorizer which implements access control for Druid, backed by Apache Ranger. Please see [the extension documentation]((https://druid.apache.org/docs/0.19.0/development/extensions-core/druid-ranger-security.html) and Authentication and Authorization for more information on the basic facilities this extension provides.
👍 # Alibaba Object Storage Service support
👀 A new 'contrib' extension has been added for Alibaba Cloud Object Storage Service (OSS) to provide both deep storage and usage as a batch ingestion input source. Since this is a 'contrib' extension, it will not be packaged by default in the binary distribution, please see community extensions for more details on how to use in your cluster.
👷 # Ingestion worker autoscaling for Google Compute Engine
Another 'contrib' extension new in 0.19.0 has been added to support ingestion worker autoscaling, which allows a Druid Overlord to provision or terminate worker instances (MiddleManagers or Indexers) whenever there are pending tasks or idle workers, for Google Compute Engine. Unlike the Amazon Web Services ingestion autoscaling extension, which provisions and terminates instances directly without using an Auto Scaling Group, the GCE autoscaler uses Managed Instance Groups to more closely align with how operators are likely to provision their clusters in GCE. Like other 'contrib' extensions, it will not be packaged by default in the binary distribution, please see community extensions for more details on how to use in your cluster.
# REGEXP_LIKE
A new
REGEXP_LIKEfunction has been added to Druid SQL and native expressions, which behaves similar toLIKE, except using regular expressions for the pattern.🌐 # Web console lookup management improvements
🌐 Druid 0.19 also web console also includes some useful improvements to the lookup table management interface. Creating and editing lookups is now done with a form to accept user input, rather than a raw text editor to enter the JSON spec.

➕ Additionally, clicking the magnifying glass icon next to a lookup will now allow displaying the first 5000 values of that lookup.

# New Coordinator per datasource 'loadstatus' API
📇 A coordinator API can make it easier to determine if the latest published segments are available for querying. This is similar to the existing coordinator 'loadstatus' API, but is datasource specific, may specify an interval, and can optionally live refresh the metadata store snapshot to get the latest up to date information. Note that operators should still exercise caution when using this API to query large numbers of segments, especially if forcing a metadata refresh, as it can potentially be a 'heavy' call on large clusters.
👍 # Native batch append support for range and hash partitioning
⬇️ Part bug fix, part new feature, Druid native batch (once again) supports appending new data to existing time chunks when those time chunks were partitioned with 'hash' or 'range' partitioning algorithms. Note that currently the appended segments only support 'dynamic' partitioning, and when rolling back to older versions that these appended segments will not be recognized by Druid after the downgrade. In order to roll back to a previous version, these appended segments should be compacted with the rest of the time chunk in order to have a homogenous partitioning scheme.
🛠 # Bug fixes
👀 Druid 0.19.0 contains 65 bug fixes, you can see the complete list here.
# Fix for batch ingested 'dynamic' partitioned segments not becoming queryable atomically
🛠 Druid 0.19.0 fixes an important query correctness issue, where 'dynamic' partitioned segments produced by a batch ingestion task were not tracking the overall number of partitions. This had the implication that when these segments came online, they did not do so as a complete set, but rather as individual segments, meaning that there would be periods of swapping where results could be queried from an incomplete partition set within a time chunk.
# Fix to allow 'hash' and 'range' partitioned segments with empty buckets to now be queryable
🛠 Prior to 0.19.0, Druid had a bug when using hash or ranged partitioning where if data skew was such that any of the buckets were 'empty' after ingesting, the partitions would never be recognized as 'complete' and so never become queryable. Druid 0.19.0 fixes this issue by adjusting the schema of the partitioning spec. These changes to the json format should be backwards compatible, however rolling back to a previous version will again make these segments no longer queryable.
# Incorrect balancer behavior
🔧 A bug in Druid versions prior to 0.19.0 allowed for (incorrect) coordinator operation in the event
druid.server.maxSizewas not set. This bug would allow segments to load, and effectively randomly balance them in the cluster (regardless of what balancer strategy was actually configured) if all historicals did not have this value set. This bug has been fixed, but as a resultdruid.server.maxSizemust be set to the sum of the segment cache location sizes for historicals, or else they will not load segments.⬆️ # Upgrading to Druid 0.19.0
🚀 Please be aware of the following issues when upgrading from 0.18.1 to 0.19.0. If you're updating from an earlier version than 0.18.1, please see the release notes of the relevant intermediate versions.
# 'druid.server.maxSize' must now be set for Historical servers
⬆️ A Coordinator bug fix as a side-effect now requires
druid.server.maxSizeto be set for segments to be loaded. While this value should have been set correctly for previous versions, please be sure this value is configured correctly before upgrading your clusters or else segments will not be loaded.🚚 # System tables 'sys.segments' column 'payload' has been removed and replaced with 'dimensions', 'metrics', and 'shardSpec'
🛰 The removal of the 'payload' column from the
sys.segmentstable should make queries on this table much more efficient, and the most useful fields from this, the list of 'dimensions', 'metrics', and the 'shardSpec', have been split out, and so are still available to devote to processing queries.0️⃣ # Changed default number of segment loading threads
🐎 The
druid.segmentCache.numLoadingThreadsconfiguration has had the default value changed from 'number of cores' to 'number of cores' divided by 6. This should make historicals a bit more well behaved out of the box when loading a large number of segments, limiting the impact on query performance.# Broadcast load rules no longer have 'colocated datasources'
🔧 A number of incomplete changes to facilitate more efficient join queries, based on the idea of utilizing broadcast load rules to propagate smaller datasources among the cluster so that join operations can be pushed down to individual segment processing, have been added to 0.19.0. While not a finished feature yet, as part of the changes to make this happen, 'broadcast' load rules no longer have the concept of 'colocated datasources', which would attempt to only broadcast segments to servers that had segments of the configured datasource. This didn't work so well in practice, as it was non-atomic, meaning that the broadcast segments would lag behind loads and drops of the colocated datasource, so we decided to remove it.
🔧 # Brokers and realtime tasks may now be configured to load segments from 'broadcast' datasources
🔧 Another effect of the afforementioned preliminary work to introduce efficient 'broadcast joins', Brokers and realtime indexing tasks will now load segments loaded by 'broadcast' rules, if a segment cache is configured. Since the feature is not complete there is little reason to do this in 0.19.0, and it will not happen unless explicitly configured.
# lpad and rpad function behavior change
0️⃣ The lpad and rpad functions have gone through a slight behavior change in Druids default non-SQL compatible mode, in order to make them behave consistently with PostgreSQL. In the new behavior, if the pad expression is an empty string, then the result will be the (possibly trimmed) original characters, rather than the empty string being treated as a null and coercing the results to null.
# Extensions providing custom Druid expressions are now expected to implement equals and hashCode methods
A change to the
Exprinterface in Druid 0.19.0 requires that any extension which provides custom expressions viaExprMacroTablemust also implementequalsandhashCodemethods to function correctly, especially with JOIN queries, which rely on filter and expression analysis for determining how to optimally process a query.# Known Issues
👀 For a full list of open issues, please see https://github.com/apache/druid/labels/Bug.
# Credits
🚀 Thanks to everyone who contributed to this release!
@2bethere
@a-chumagin
@a2l007
@abhishekrb19
@agricenko
@ahuret
@alex-plekhanov
@AlexanderSaydakov
@awelsh93
@bolkedebruin
@calvinhkf
@capistrant
@ccaominh
@chenyuzhi459
👕 @clintropolis
@damnMeddlingKid
@danc
@dylwylie
@egor-ryashin
@FrankChen021
@frnidito
@Fullstop000
@gianm
@harshpreet93
@jihoonson
@jon-wei
@josephglanville
@kamaci
@kanibs
@leerho
@liujianhuanzz
@maytasm
@mcbrewster
@mghosh4
@morrifeldman
@pjain1
@samarthjain
@stefanbirkner
@sthetland
@suneet-s
@surekhasaharan
@tarpdalton
@viongpanzi
@vogievetsky
@willsalz
@wjhypo
@xhl0726
@xiangqiao123
@xvrl
@yuanlihan
@zachjsh